I am a 4th year CS PhD student at University of Maryland, College Park advised by Prof. Dinesh Manocha. I am broadly interested in multi-modal learning and its different applications. My research primarily involves studying the interplay between the vision and audio modalities and developing systems equipped with their comprehensive understanding.
I am currently working as a ML Research intern at Apple MLR hosted by Chun-Liang Li and Karren Yang. I spent the summer of '24 at Meta Reality Labs working as a research scientist intern hosted by Ruohan Gao . Before this, I was a student researcher at Google Research with Avisek Lahiri and Vivek Kwatra in the Talking heads team on speech driven facial synthesis. Previously, I spent a wonderful summer with Adobe Research working with Joseph K J in the Multi-modal AI team as a research PhD intern on multi-modal audio generation. I am also fortunate to have had the chance to work with Prof. Kristen Grauman , Prof. Salman Khan , Prof. Mohamed Elhoseiny among other wonderful mentors and collaborators.
Before joining for PhD, I was working as a Machine Learning Scientist with the Camera and Video AI team at ShareChat, India. I was also a visiting researcher at the Computer Vision and Pattern Recognition Unit at Indian Statistical Institute Kolkata under Prof. Ujjwal Bhattacharya. Even before, I was a Senior Research Engineer with the Vision Intelligence Group at Samsung R&D Institute Bangalore. I primarily worked on developing novel AI-powered solutions for different smart devices of Samsung.
I received my MTech in Computer Science & Engineering from IIIT Hyderabad where I was fortunate to be advised by Prof. C V Jawahar. During my undergrad, I worked as a research intern under Prof. Pabitra Mitra at IIT Kharagpur and the CVPR Unit at ISI Kolkata.
-
Looking for Internship/Industrial RS/Post-Doc Positions:
I am actively looking for internships, full-time industrial RS and Post-Doc positions
in multi-modal learning, generative modeling, agentic AI and relevant areas. Kindly reach out if you think I would be a good fit.
-
Feel free to reach out if you're interested in research collaboration!
Email /
GitHub /
Google Scholar /
LinkedIn /
Twitter
|

|
Selected publications
I am interested in solving Computer Vision, Computer Audition, and Machine Learning problems and applying them to broad AI
applications. My research focuses on applying multi-modal learning (Vision + X) for generative modeling and holistic cross-modal understanding
with minimal supervision. In the past, I have focused on computational photography, tackling
challenges such as image reflection removal, intrinsic image decomposition, inverse rendering and video quality assessment.
Representative papers are highlighted. For full list of publications, please refer to
my Google Scholar.
|
|
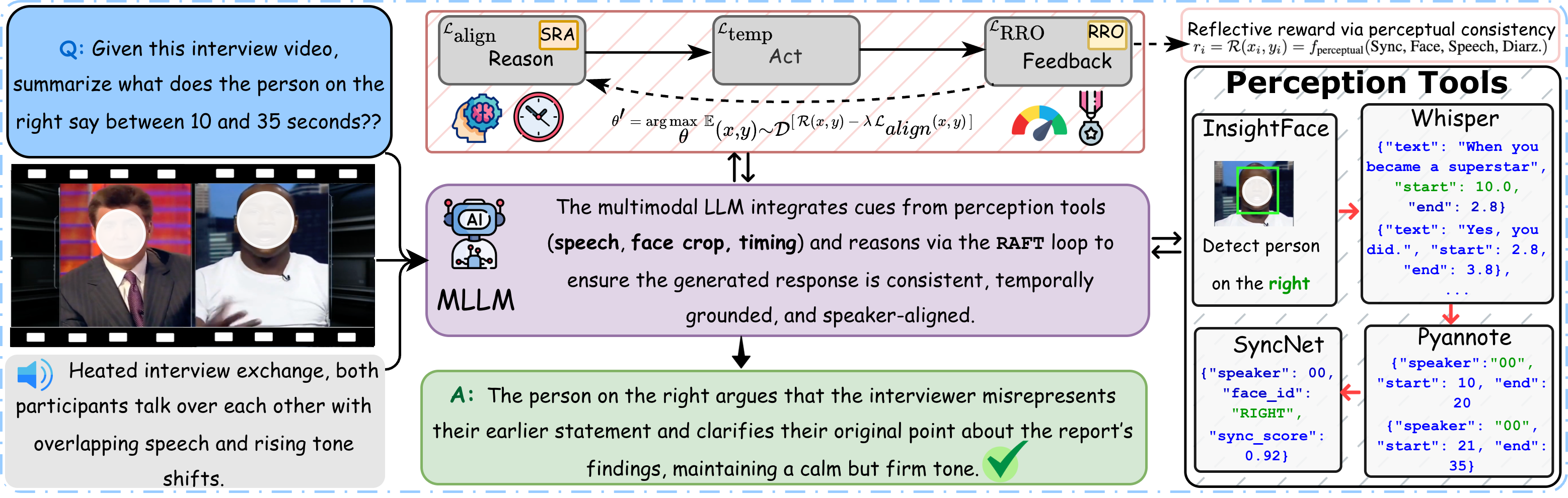
  AMusE: Audio-Visual Benchmark and Alignment Framework for Agentic Multi-Speaker Understanding AMusE: Audio-Visual Benchmark and Alignment Framework for Agentic Multi-Speaker Understanding
Sanjoy Chowdhury, Karren D. Yang, Xudong Liu, Fartash Faghri, Pavan Kumar Anasosalu Vasu, Oncel Tuzel, Dinesh Manocha, Chun-Liang Li, Raviteja Vemulapalli
Paper /
Project Page (Coming soon) /
|
|
 MAGNET: A Multi-agent Framework for Finding Audio-Visual Needles by Reasoning over Multi-Video Haystacks MAGNET: A Multi-agent Framework for Finding Audio-Visual Needles by Reasoning over Multi-Video Haystacks
Sanjoy Chowdhury, Mohamed Elmoghany, Yohan Abeysinghe, Junjie Fei, Sayan Nag, Salman Khan, Mohamed Elhoseiny, Dinesh Manocha
Annual Conference on Neural Information Processing Systems (NeurIPS), 2025
Paper /
Project Page /
Poster /
Huggingface /
Kaggle /
Code
|
|
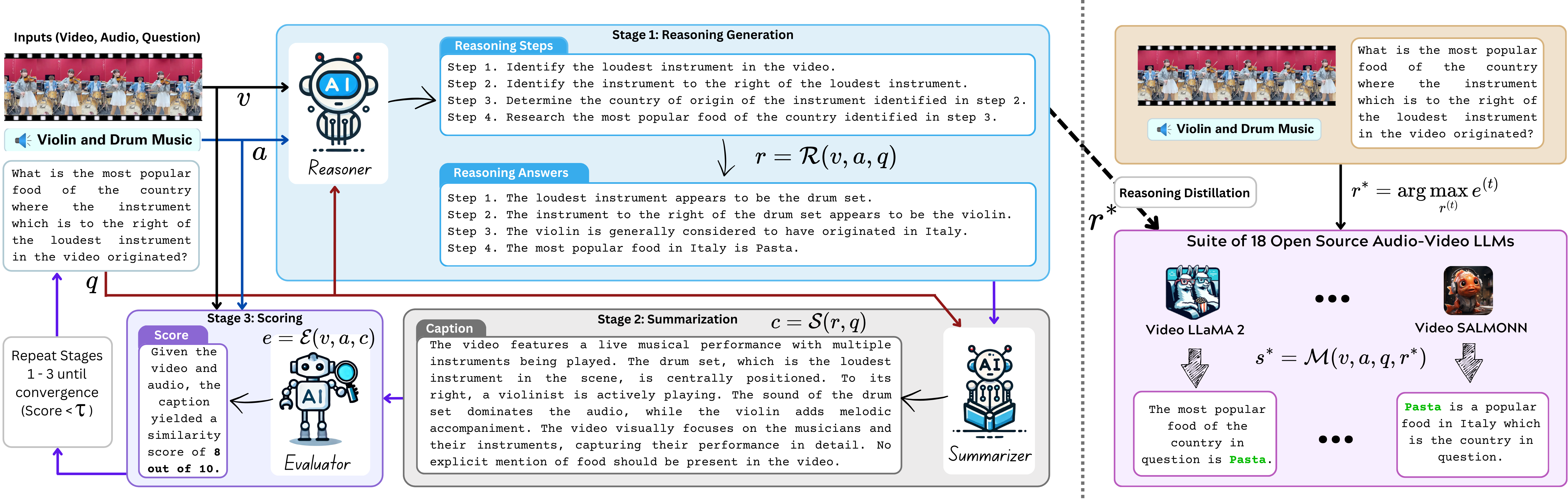
 AURELIA: Test-time Reasoning Distillation in Audio-Visual LLMs AURELIA: Test-time Reasoning Distillation in Audio-Visual LLMs
Sanjoy Chowdhury*, Hanan Gani*, Nishit Anand, Sayan Nag, Ruohan Gao, Mohamed Elhoseiny, Salman Khan, Dinesh Manocha
International Conference on Computer Vision (ICCV), 2025
Paper /
Project Page /
Code
|
|
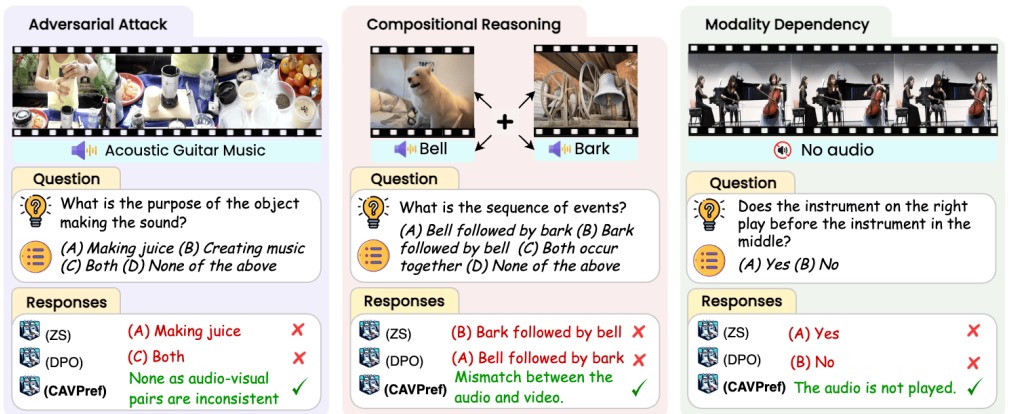
AVTrustBench: Assessing and Enhancing Reliability and Robustness in Audio-Visual LLMs
Sanjoy Chowdhury*, Sayan Nag*, Subhrajyoti Dasgupta, Yaoting Wang, Mohamed Elhoseiny, Ruohan Gao, Dinesh Manocha
International Conference on Computer Vision (ICCV), 2025
Paper /
Project Page /
Code
|
|
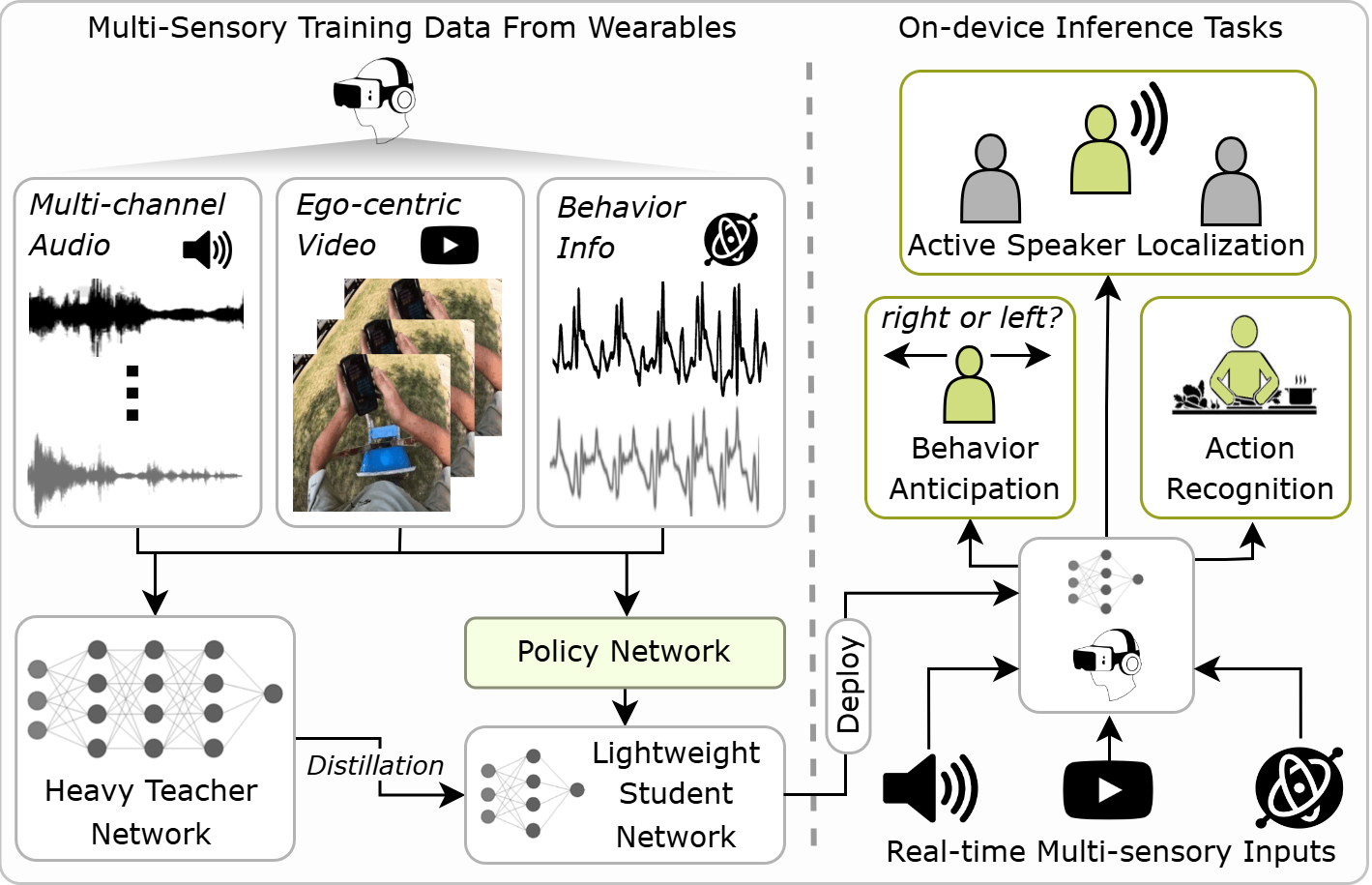
EgoAdapt: Adaptive Multisensory Distillation and Policy Learning for Efficient Egocentric Perception
Sanjoy Chowdhury, Subrata Biswas, Sayan Nag, Tushar Nagarajan, Calvin Murdock, Ishwarya Ananthabhotla, Yijun Qian, Vamsi Krishna Ithapu, Dinesh Manocha, Ruohan Gao
International Conference on Computer Vision (ICCV), 2025
Paper /
Project Page /
Code
|
|
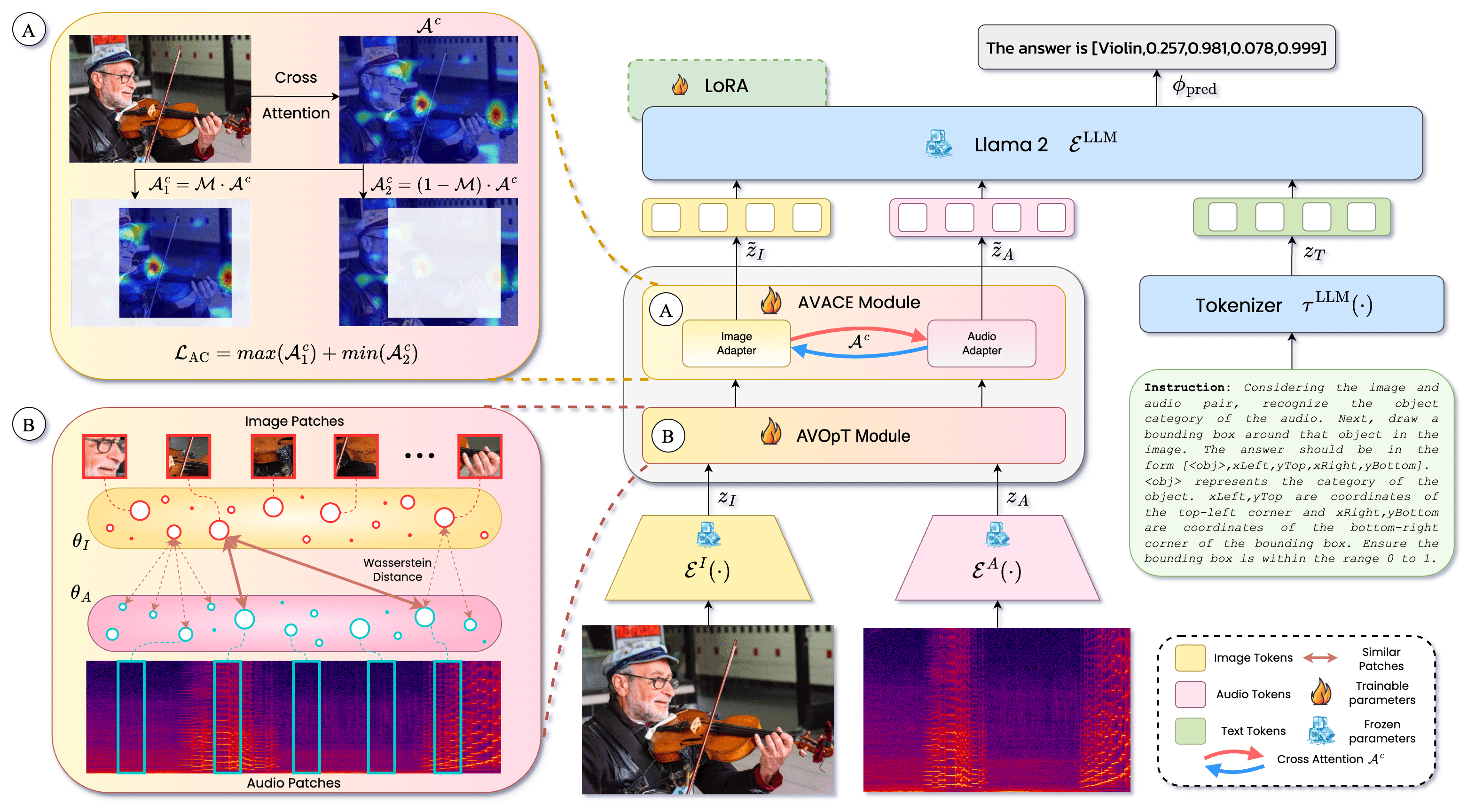
 Meerkat: Audio-Visual Large Language Model for Grounding in Space and Time Meerkat: Audio-Visual Large Language Model for Grounding in Space and Time
Sanjoy Chowdhury*, Sayan Nag*, Subhrajyoti Dasgupta*, Jun Chen, Mohamed Elhoseiny, Ruohan Gao, Dinesh Manocha
European Conference on Computer Vision (ECCV), 2024
Paper/
Project Page /
Poster /
Video /
Dataset /
Code
|
|
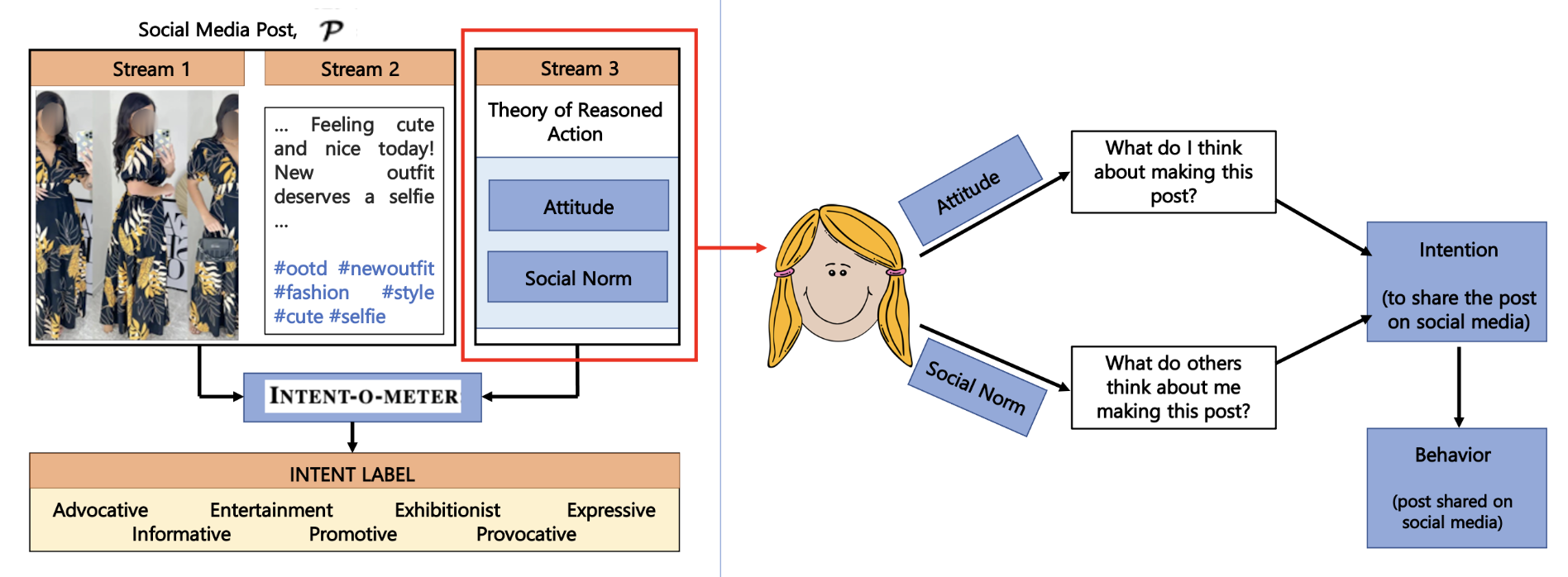
Towards Determining Perceived Human Intent for Multimodal Social Media Posts using The Theory of Reasoned Action
Trisha Mittal, Sanjoy Chowdhury, Pooja Guhan, Snikhita Chelluri, Dinesh Manocha
Nature Scientific Reports, 2024
Paper /
Dataset
|
|
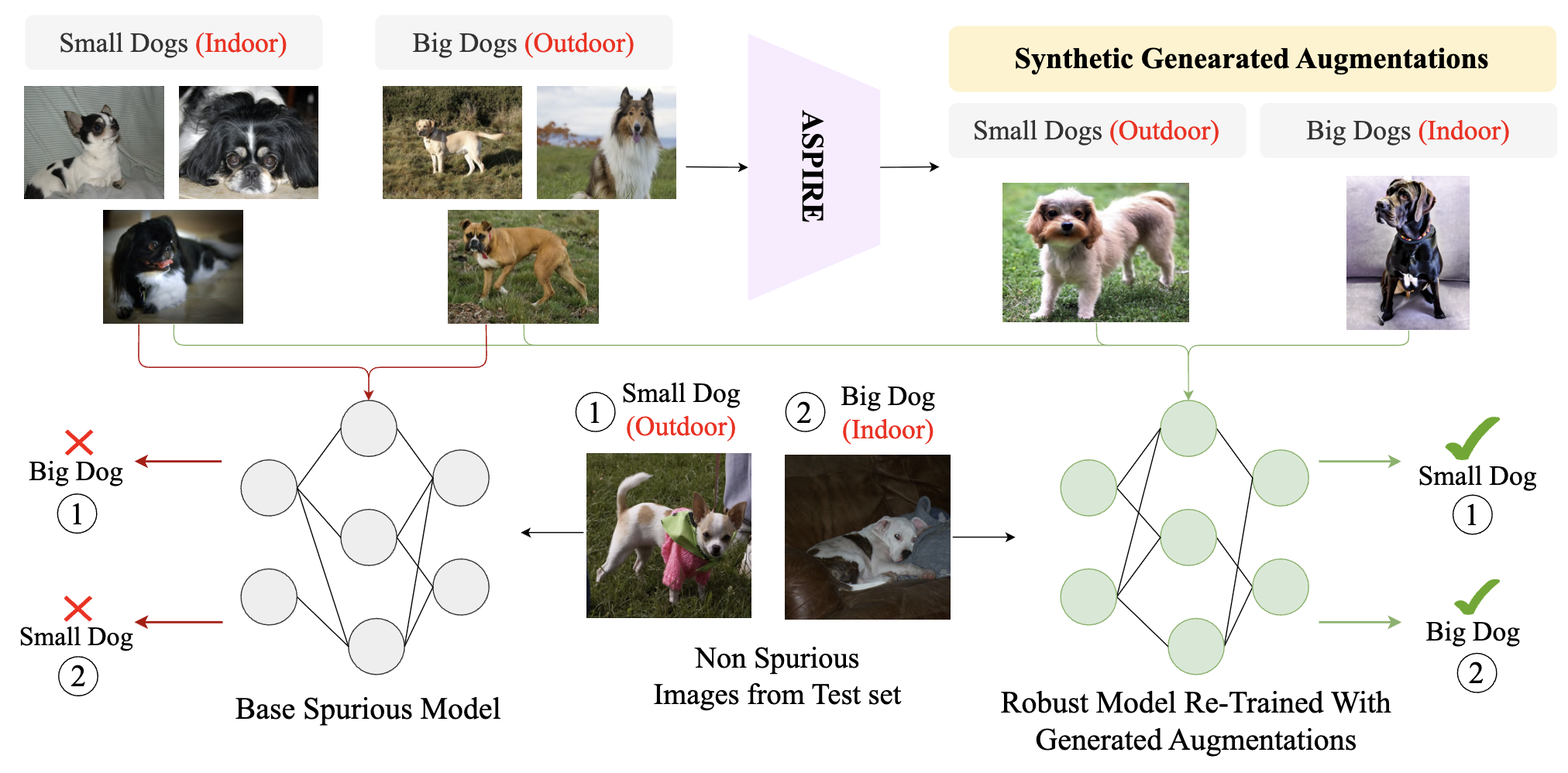
ASPIRE: Language-Guided Data Augmentation for Improving Robustness Against Spurious Correlations
Sreyan Ghosh*, Chandra Kiran Reddy Evuru*, Sonal Kumar, Utkarsh Tyagi, Sakshi Singh, Sanjoy Chowdhury, Dinesh Manocha
Association for Computational Linguistics(ACL Findings), 2024
Paper /
Code
|
|
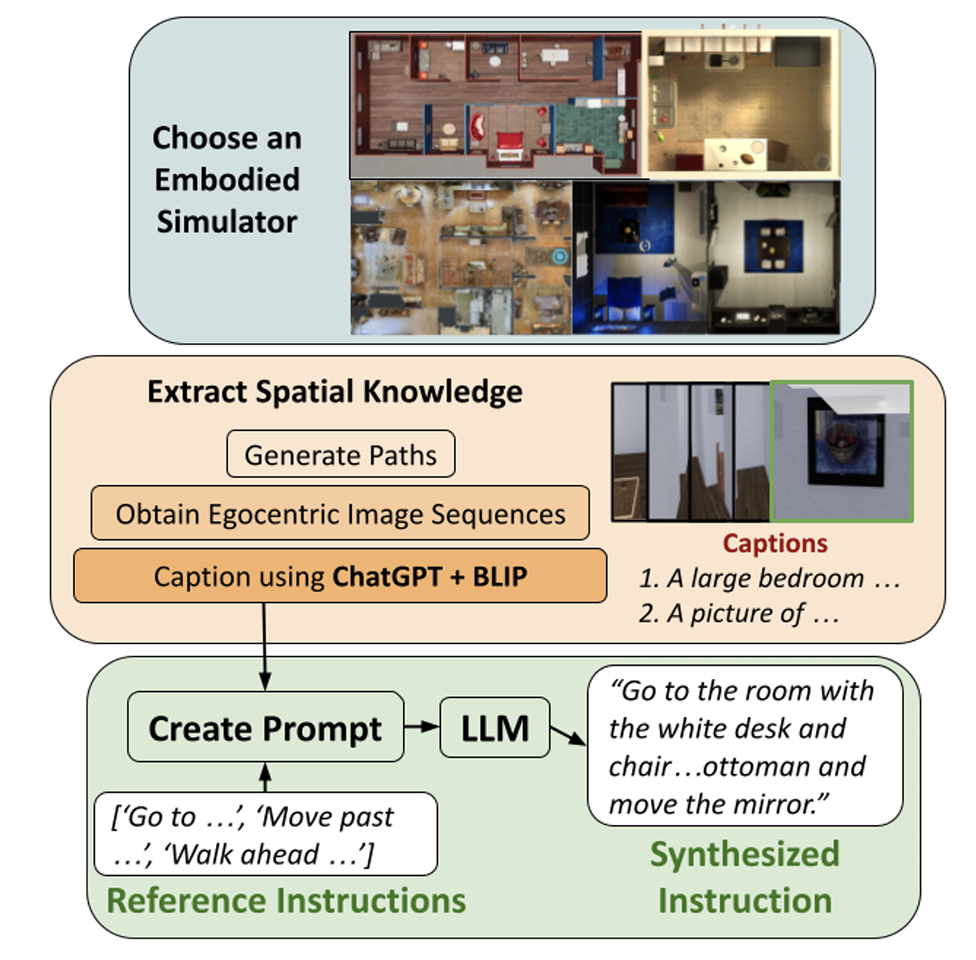
Can LLM’s Generate Human-Like Wayfinding Instructions? Towards Platform-Agnostic Embodied Instruction Synthesis
Vishnu Sashank Dorbala, Sanjoy Chowdhury, Dinesh Manocha
North American Chapter of the Association for Computational Linguistics (NAACL), 2024
Paper
|
|
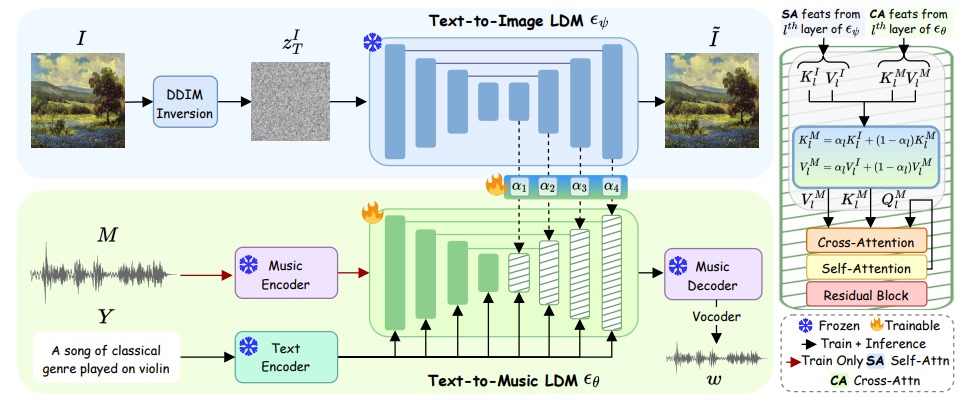
MeLFusion: Synthesizing Music from Image and Language Cues using Diffusion Models (Highlight, Top 2.8%)
Sanjoy Chowdhury*, Sayan Nag*, Joseph KJ, Balaji Vasan Srinivasan, Dinesh Manocha
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Paper/
Project Page /
Poster /
Video /
Dataset /
Code
|
|
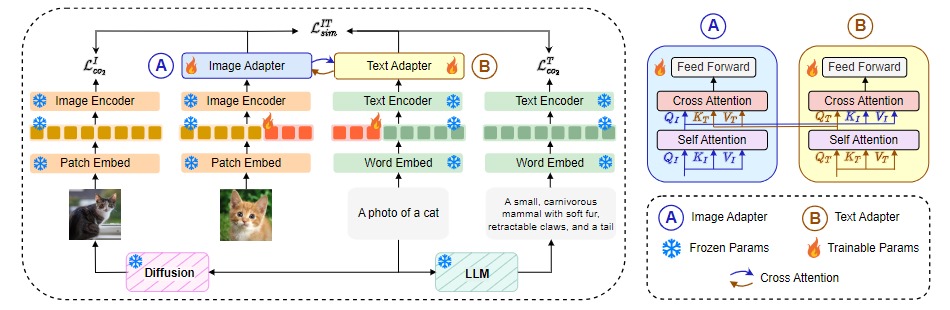
APoLLo  : Unified Adapter and Prompt Learning for Vision Language Models : Unified Adapter and Prompt Learning for Vision Language Models
Sanjoy Chowdhury*, Sayan Nag*, Dinesh Manocha
Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
Paper /
Project Page /
Poster /
Video /
Code
|
|
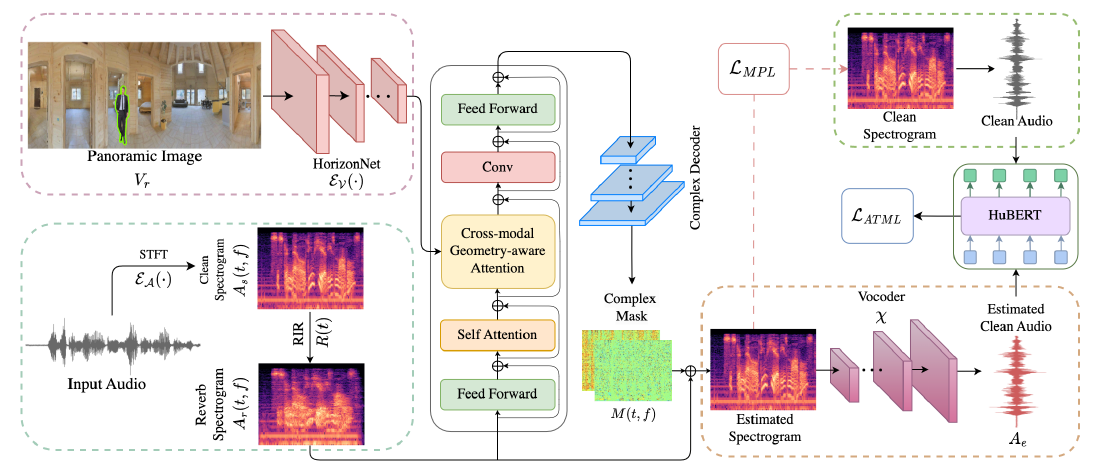
AdVerb: Visually Guided Audio Dereverberation
Sanjoy Chowdhury*, Sreyan Ghosh*, Subhrajyoti Dasgupta, Anton Ratnarajah, Utkarsh Tyagi, Dinesh Manocha
International Conference on Computer Vision (ICCV), 2023
Paper /
Project Page /
Video /
Poster /
Code
|
|
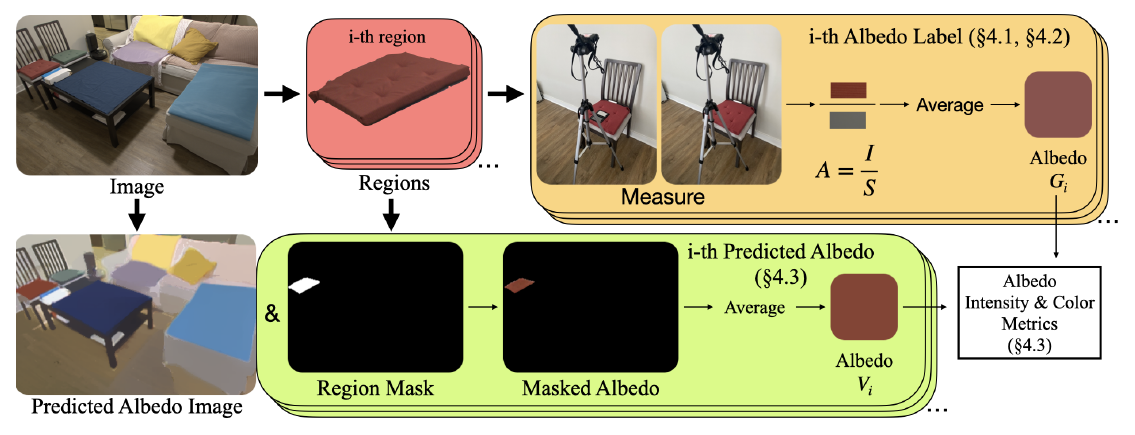
Measured Albedo in the Wild: Filling the Gap in Intrinsics Evaluation
Jiaye Wu, Sanjoy Chowdhury, Hariharmano Shanmugaraja, David Jacobs, Soumyadip Sengupta
International Conference on Computational Photography (ICCP), 2023
Paper /
Project Page /
Dataset
|
|
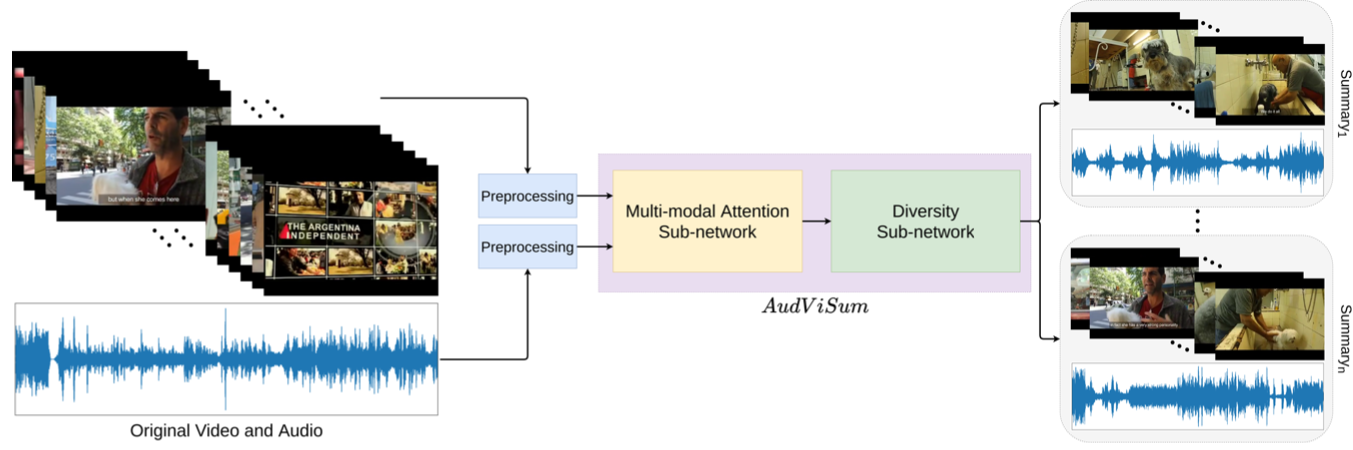
AudViSum: Self-Supervised Deep Reinforcement Learning for Diverse Audio-Visual Summary Generation
Sanjoy Chowdhury*, Aditya P. Patra*, Subhrajyoti Dasgupta, Ujjwal Bhattacharya
British Machine Vision Conference (BMVC), 2021
Paper /
Code /
Presentation
|
|
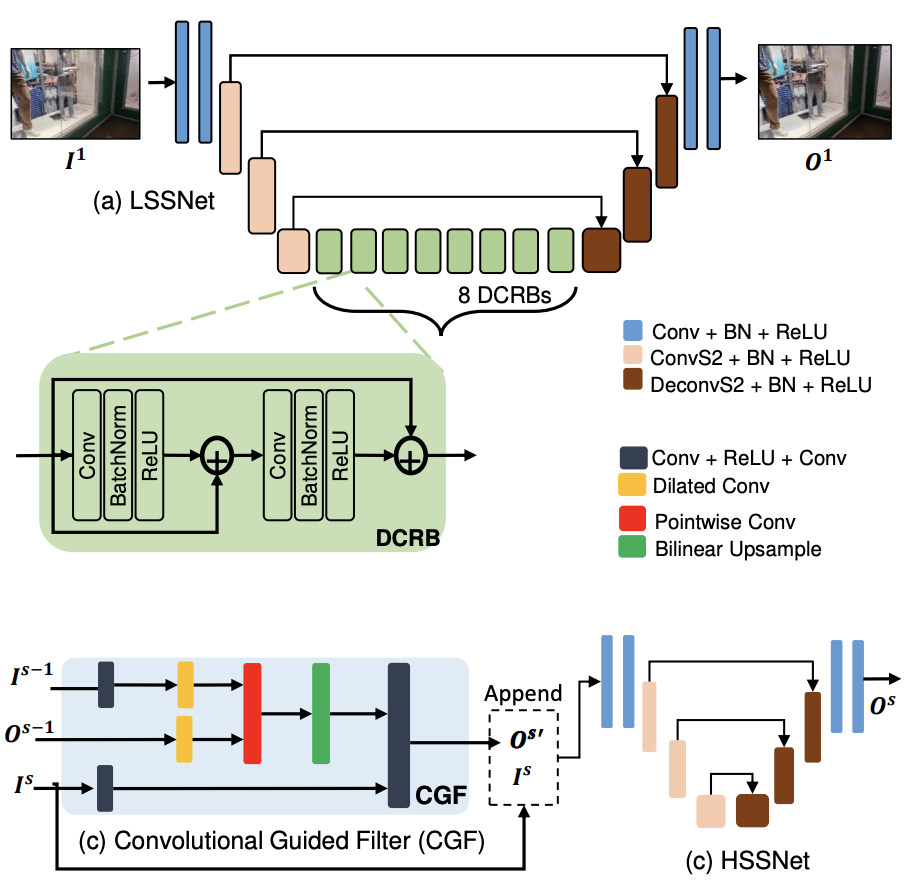
V-DESIRR: Very Fast Deep Embedded Single Image Reflection Removal
B H Pawan Prasad, Green Rosh K S, Lokesh R B, Kaushik Mitra, Sanjoy Chowdhury
International Conference on Computer Vision (ICCV), 2021
Paper /
Code
|

|
Listen to the Pixels
Sanjoy Chowdhury, Subhrajyoti Dasgupta, Sudip Das, Ujjwal Bhattacharya
International Conference on Image Processing (ICIP), 2021
Paper /
Code /
Presentation
|
Affiliations

IIT Kharagpur
Apr-Sep 2016
|

ISI Kolkata
Feb-July 2017
|

IIIT Hyderabad
Aug 2017 - May 2019
|

Mentor Graphics Hyderabad
May - July 2018
|

Samsung Research Bangalore
June 2019 - June 2021
|

ShareChat Bangalore
June 2021 - May 2022
|

UMD College Park
Aug 2022 - Present
|

Adobe Research
May 2023 - Aug 2023
|

KAUST
Jan 2024 - Present
|

Google Research
Feb 2024 - May 2024
|

Meta AI
May 2024 - Nov 2024
|

Apple MLR
Mar 2025 - Aug 2025
|
|
|